
学习redisbook, 了解redis设计和原理
redisbook介绍
redisbook是huangjianhong大神写的,介绍redis设计和实现的一本,redis入门提高很好的一本书。
相关学习资源
- 带注释的redis源码
- redisbook网站
- redis pdf 版本下载 pdf版本已经大概看了一遍,确实对redis设计以及底层实现有了一些了解.
目录
- 内部数据结构
- sds
- 双端链表
- 字典
- 跳跃表
- 内存数据结构
- intset,整数集合
- 压缩列表
- Redis数据类型
- 字符串
- 哈希表
- 列表
- 集合
- 有序集合
- 功能实现
- 事务
- 订阅发布
- lua 脚本
- 慢查询日志
- 过期淘汰
- 持久化
redisbook学习心得
逼迫自己静下心来做自己抵触的事情,一定会有收获的。
redis内部数据结构
0.简单动态字符串(simple dynamic string, sds)
redis sds 的实现如下:
1
2
3
4
5
struct sdshdr {
int len; // buf已用长度
int free; // buf可用的长度
char buf[]; //实际存储字符串数据的地方
}
基于如上sds的实现,redis字符串有如下特征:
- redis的字符串是使用sds来表示的,而不是c字符串
- 和 c字符串比较,sds有以下特性:
- 高效地获得字符串长度,O(1)
- 高效的执行追加操作
- 二进制安全
- sds为追加操作进行追加优化,加快追加操作的速度,降低内存分配的次数,代价是多占用一些内存,而且这些内存不会主动释放
1.双端列表
双端链表的实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
//双端链表的节点
typedef struct listNode {
//前驱节点
struct listNode *prev;
//后驱节点
struct listNode *next;
//值
void *value;
}listNode;
//双端链表的定义
typedef struct list {
//表头指针
listNode *head;
//表尾指针
listNode *tail;
unsigned long len; // 节点数量
//复制函数
void *(*dup) (void *ptr);
//释放函数
void (*free) (void * ptr);
//比较函数
int (*match) (void *ptr, void *key);
} list;
基于如上双端列表的实现,双端链表有如下特征:
- 链表带有前后驱的节点的指针,访问前后驱节点的负责度为O(1),并且链表可以进行两个方向上的迭代。
- 链表带有前后驱节点的指针,在头或者尾进行增加或者删除节点的复杂度为O(1).
- 链表带有记录链表长度的字段,可以O(1)获得链表的长度
2.字典
字典实现有多种方式,元素个数不多时,可以通过链表和数组来实现;元素个数达到一定数量级后可以考虑哈希表;还有一种更为复杂的平衡树实现。
字典的hash表实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
//每个字典有两个hash表,来实现渐进式rehash
typedef struct dict {
//特定类型的处理函数
dictType *type;
//类型处理函数的私有数据
void *privdata;
//哈希表2个
dictht ht[2];
// 记录rehash进度
int rehashidx;
//迭代器的数量
int iterators;
}dict;
//哈希表的实现
typedef struct dictht {
//哈希表节点指针的数组
dictEntry **table;
//指针数组的大小
unsigned long size;
//指针数组的长度掩码,用来计算索引值
unsigned long sizemark;
//哈希表现有节点数量
unsigned long used;
}dictht;
//table元素是个数组,数组中每个元素指向dictEntry结构体的指针。
//hash表节点的结构体
typedef struct dictEntry {
//键
void *key;
//值
union {
void *val;
uint64_t u64;
int64_t s64;
}v;
//后继节点
dictEntry *next;
}dictEntry;
//next属性指向另一个dictEntry节点,dictht是通过链地址来解决hash碰撞。
//当不同的键有相同的hash值时,dictht通过一个链表来链接起来这些key-value对的dictEntry。
redis字典的实现可以用下图表示
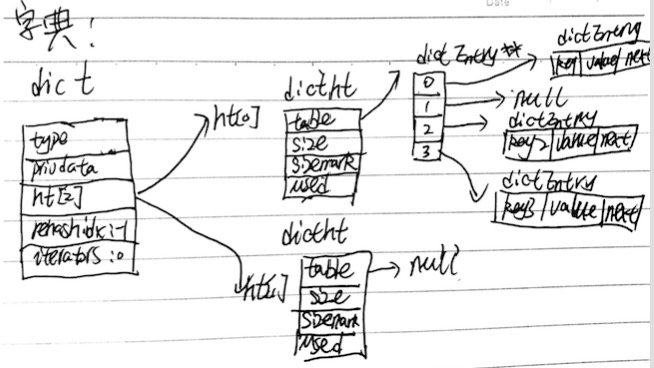
字典的特征
- 字典是由键值对构成的抽象的数据类型
- Redis 中的数据库和哈希键都基于字典来实现
- Redis 字典的底层实现为哈希表,每个字典有两个hash表,一般情况下只使用0号哈希表,只有在rehash进行时,才会同时使用0号和1号哈希表。
- 哈希表是使用链地址的方式来解决键冲突的问题
- Rehash 可以用于扩展或收缩哈希表
- 对哈希表进行rehash,是分多次,渐进式完成的
3.跳跃表
3.0 参考
* [跳跃表](http://blog.sina.com.cn/s/blog_60707c0f0100wudj.html)
3.1 跳跃表中查找元素时间复杂度O(logN):
在跳跃表中查找一个元素x,按照如下几个步骤进行:
从最上层的链的开头开始假设当前位置为p,它向右指向的节点为q(p与q不一定相邻),且q的值为y。 将y与x作比较: 如果x=y,输出查询成功,输出相关信息; 如果x大于y,从p向右移动到q的位置; 如果x小于y,从p向下移动一格, 如果当前位置在最底层的链S0中,且还要往下移动的话,则输出查询失败。
3.2跳跃表的结构定义
如下zskiplist和zskiplistNode定义都在redis.h头文件中.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
typedef zskiplist struct {
zskiplistNode *header, *tail;
unsigned long length;
int level;
}zskiplist;
typedef zskiplistNode struct {
robj *robj;
double score;
struct zskiplistNode *backward;
struct zkiplistlevel {
struct zskiplistNode *forward;
unsigned span; //跨越节点的数量
} level[];
} zskiplistNode;
跳跃表中各节点是按照value来有序存储的,所以跳跃表的删除、插入、查找一个元素的时间复杂度都是O(logN).
内存数据结构
- 虽然内部数据结构足够强大,但是创建一套完整的数据结构本身就是一套非常费内存的工作, 当一个对象包含的元素并不多,或者元素体积并不大时,使用代价高昂的内部数据结构并不是最好的办法
- 为了解决如上问题,redis在特定条件下会使用内存数据结构。
- 内存映射数据结构是一系列特殊编码的字节序列,创建他们所需要的内存通常比左右类似的内部数据结构要少的多,使用得当可以节省大量内存。
- 但是内存数据结构的编码方式比内部数据结构的要复杂,所以内存数据结构所占用的CPU 时间会比作用类似的内部数据结构要多。
Redis中内存映射数据结构有两种1.intset, 2.压缩列表
1. 整数集合
整数集合用来保存有序、无重复的多个整数值,它会根据元素的值,自动想选择该用什么长度的整形类型来保存数据,是用最长类型元素的类型来保存所有的元素, 新元素的加入可能会改变整数集合的编码类型,可能要变成更大空间的类型来存储所有的元素
整数集合的数据结构
定义在intset.h中可以找到,详细如下:
1
2
3
4
5
typedef struct intset {
uint32_t encoding; //保存元素所使用的类型的长度
uint32_t length; //整数集合中元素个数
int8_t contents[]; //保存元素的数组
}intset;
encoding的值可以是如下三种的一种:
1
2
3
\#define INTSET_ENC_INT16 (sizeof(int16_t))
\#define INTSET_ENC_INT32 (sizeof(int32_t))
\#define INTSET_ENC_INT64 (sizeof(int64_t))
contents 是实际存放元素的地方,数组中的元素有如下两个特性:
- 没有重复元素
- 元素在数组中从小到大排序。
intset 特征总结
- intset 用来存储有序、不重复的整形数据,它会根据元素的值,选择该用什么长度的整数类型来保存元素
- 当一个位长度更长的整数值添加到intset时,需要对intset进行升级,升级后的intset中的元素的位长度都等于新加元素的位长度,但元素值保持不变。
- 升级涉及对每个元素进行内存重分配和移动,时间复杂度是O(N)
- intset是有序的,使用二分法来查找元素,时间复杂度O(logN)
2. 压缩列表
ziplist是一系列特殊编码的内存块构成的列表,一个ziplist可以包括多个节点entry,每个节点可以保存一个长度受限制的 字符数据或者整数.
2. ziplist的结构
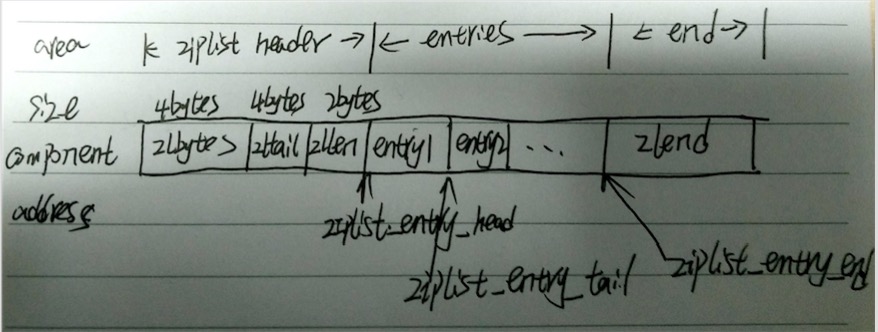
下面分别解释途中每个字段的含义:
- zlbytes: uint32_t 表示整个ziplist的字节数,用来重新分配内存或者计算末端使用
- zltail: uint32_t 到达整个ziplist表尾的偏移量,通过这个偏移量可以在不遍历整个列表的前提下,获得表尾节点
- zllen: uint16_t ziplist中节点(entry)的数量
- entryX : 节点,entry的结构见下图
- zlend: uint8_t 用来标记ziplist末端

下面介绍些ziplist节点每个字段的含义:
- pre_entry_length: 上一个节点的长度,通过这个值,可以进行指针计算,从而跳到上一个节点
- encoding && length: encoding 和length共同决定了content中保存数据的数据类型以及长度。
- content: 是节点的实际数据内容
ziplist总结
添加或者删除ziplist节点,可能会引起连锁更新,最坏时间复杂度是O(N^2), 不过连锁更新的概率不高,所以一般时间复杂度是O(N).
Redis 数据类型
Redis中每个数据类型的对象都应该有个类型信息,并且redis每个数据类型的底层实现也有多种,实现方式在redis称为编码(encoding)方式, 比如集合可以用intset或者hash表两种底层实现方式(编码方式).
类型系统应该包括如下功能:
- 检查数据类型
- 检查数据编码(encoding)方式
- 数据所占空间分配,销毁和分享等
0. RedisObject 定义
typedef struct redisObject {
unsigned type:4; //对象类型
unsigned encoding:4; //编码方式
unsigned lru:24; //LRU
int refcount; //引用计数
void *ptr; //指向robj对象对应的值
}robj;
其中, type是对象类型,可以有如下5种类型:
#define REDIS_STRING 0
#define REDIS_LIST 1
#define REDIS_SET 2
#define REDIS_ZSET 3
#define REDIS_HASH 4
encoding 记录了对象的编码方式,可以有如下编码方式:
/* Objects encoding. Some kind of objects like Strings and Hashes can be
* internally represented in multiple ways. The 'encoding' field of the object
* * is set to one of this fields for this object.
* */
#define REDIS_ENCODING_RAW 0 /* Raw representation */
#define REDIS_ENCODING_INT 1 /* Encoded as integer */
#define REDIS_ENCODING_HT 2 /* Encoded as hash table */
#define REDIS_ENCODING_ZIPMAP 3 /* Encoded as zipmap */
#define REDIS_ENCODING_LINKEDLIST 4 /* Encoded as regular linked list */
#define REDIS_ENCODING_ZIPLIST 5 /* Encoded as ziplist */
#define REDIS_ENCODING_INTSET 6 /* Encoded as intset */
#define REDIS_ENCODING_SKIPLIST 7 /* Encoded as skiplist */
#define REDIS_ENCODING_EMBSTR 8 /* Embedded sds string encoding */
ptr指向这个对象实际包括的值,如一个字典,一个列表,一个集合等。
通过下图给出redisObject中类型和编码的关系:
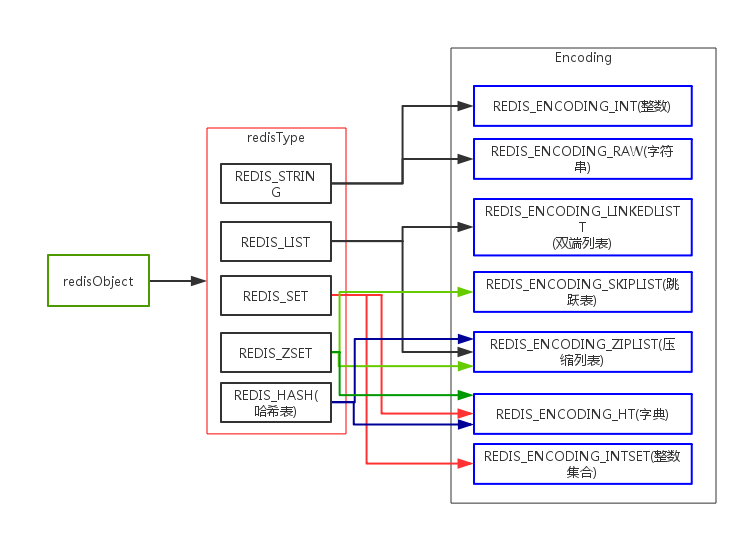
redis执行一个处理数据类型的命令需要进行如下步骤:
- 根据key在数据库的key空间中(数据库字典)中查找对应的RedisObject,如果没有找到则返回NULL.
- 检查RedisObject 的type属性,判断执行的命令是否和robj的类型相符合,若不符合,则返回类型错误.
- 根据redisObject encoding编码信息,选择合适的操作函数来处理底层数据结构.
- 数据结构操作的结果作为命令的返回值
redis引用计数以及对象销毁机制
Redis的对象系统使用引用计数技术来负责维持和销毁对象,引用计数技术的机制如下:
- 每个redisObject 都有个refcount属性,指示这个对象被引用了多少次。
- 当创建一个redisObject时,refcount 设置为1.
- 当对一个对象进行共享时,它的refcount属性的值增加1.
- 当用完一个对象或者取消对一个对象的共享时,对象的refcount减小1.
- 当对象的refcount变为0时,这个redisObject结构,以及它所引用的数据结构的内存都将被释放。
1.数据类型—字符串 REDIS_STRING
RedisObject 字符串类型有两种编码格式REDIS_ENCODING_RAW 和 REDIS_ENCODING_INT,
- REDIS_ENCODING_INT 用来保存long类型值
- REDIS_ENCODING_RAW 使用sds来保存字符串、long long、double以及long double.
Redis为字符串类型选择的编码默认是REDIS_ENCODING_RAW。
2.数据类型—哈希表 REDIS_HASH
RedisObject 哈希表类型也有两种编码方式,REDIS_ENCODING_ZIPLIST 和 REDIS_ENCODING_HT
Redis_HASH 的默认编码类型是REDIS_ENCODING_ZIPLIST(压缩列表),当如下两个条件满足任一个时,编码从REDIS_ENCODING_ZIPLIST 切换到REDIS_ENCODING_HT:
- 哈希表中某个键或者某个值的长度大于server.hash_max_ziplist_value (默认是64字节)。
- 压缩列表中节点数量大于server.hash_max_ziplist_entries (默认是512)。
ZIPLIST来存储哈希表时,Key-Value是顺序存储的。
3.数据类型—列表 REDIS_LIST
RedisObject 列表类型也有两种编码方式压缩列表REDIS_ENCODING_ZIPLIST 和 双端列表REDIS_ENCODING_LINKEDLIST
编码选择:创建一个列表时,默认的编码方式是: REDIS_ENCODING_ZIPLIST压缩列表, 当下列某一个条件满足时,列表编码方式会切换成 REDIS_ENCODING_LINKEDLIST双端列表:
- 试图向列表中插入一个字符串值,且这个字符串长度超过server.list_max_ziplist_value(默认是64字节);
- ziplist包含节点超过server.list_max_ziplist_entries(默认是512)。
4.数据类型—集合 REDIS_SET
RedisObject 集合类型有两种编码方式:REDIS_ENCODING_INTSET(整数集合)和 REDIS_ENCODING_HT(字典)
编码选择
第一个添加到集合中的元素,决定了创建集合的编码:
- 若的第一个元素可以表示为long long 整数类型,那么集合初始编码类型是REDIS_ENCODING_INTSET
- 否则,集合的编码类型为REDIS_ENCODING_HT(字典)
编码切换
如果集合用REDIS_ENCODING_INTSET编码,那么当下面任一个条件满足时,编码类型都会转换为REDIS_ENCODING_HT
- intset 保存的整数的个数超过了server.set_max_intset_entries(默认是512).
- 试图往集合里面加一个新元素,并且这个新元素不能被long long类型表示时(也就是新元素不是整数时)。
5.数据类型—有序集合 REDIS_ZSET
RedisObject 有序集类型有两种编码方式,一种是压缩列表REDIS_ENCODING_ZIPLIST, 一种是通过skiplist跳跃表和字典共同实现。
编码选择
zadd添加一个元素到一个空的有序集时,如果有序集同时满足如下条件,则用REDIS_ENCODING_ZIPLIST编码方式:
- 服务器属性server.zset_ziplist_max_entries的值大于0(默认是128)
- 新元素的值小于server.zset_ziplist_max_value的值,默认是64字节
编码切换
对于一个压缩列表编码的有序集,若满足如下任一个条件,则有序集的编码转换为跳跃表和字典编码方式:
- ziplist压缩列表所保存的元素个数超过了server.zset_ziplist_max_entries的值,默认是128
- 新添加的元素的member的长度大于服务器属性server.zset_ziplist_max_value的值,默认是64字节。
有序集通过字典来实现通过key查找的O(1)复杂度, 用跳跃表来保证按照score查找的O(logN)的复杂度.
四、功能实现
1. 事务
redis 通过mutil discard exec 和 watch来实现事务操作。
一个完整的事务包括:
- 开始事务(multi), 执行mutil之后redis客户端的redis_multi选项打开,客户端从非事务状态转化为事务状态。
- 命令入队, 非事务状态的客户端发送给server的命令会被立即执行并返回执行结果;事务状态的客户端发送给server的命令会被加入事务队列,并返回
QUEUED. - 执行事务(exec), 事务队列是一个数组,每个数组元素都包含三个属性:要执行的命令,命令的参数,命令参数的个数。执行事务阶段会根据FIFO来执行事务队列中的命令,执行每个命令的结果加入回复队列中,所有命令执行完后,把回复队列的结果返回给客户端。
另外两个事务相关的命令
- discard, discard命令用于取消事务,它清空客户端相关的整个事务队列,然后将客户端从事务状态调整到非事务状态,最后返回字符串OK给客户端,说明事务取消成功。
- watch, watch 只能在客户端进入事务状态之前执行,来监视任意数量的键,当调用exec时,如果任意一个被监视的键,被其他客户端修改,那么整个事务不再执行,直接返回失败。
1.1watch 命令的实现
每一个代表数据库的redis.h/redisDb数据结构中,都保存了一个watched_keys字典,字典的键就是被监视的键, 字典的值是一个链表,保存了那些客户端监视了这个键
redisDb的数据结构如下:
typedef struct redisDb {
dict *dict; //redis数据库的见空间
dict *expire; // 设置有效期的key的一个字典
dict *blocking_keys; // 处于堵塞状态的键
dict *ready_keys; //被堵塞,但已经有数据的键
dict *watched_keys; // 事务前被监视的键
struct evictionPoolEntry *eviction_pool; /* Eviction pool of keys */
int id; //数据库编号
long long avg_ttl; //平均有效期,统计用的
}redisDb;
1.2 wacth 命令的触发
- 在任何对数据库的键空间进行修改的命令执行成功之后,multi/touchWatchKey函数都会被调用, touchWatchKey函数会检查数据库的 watched_keys字典,看是否有客户端在监听被本命令修改的键,如果有的话,程序会将所有监视被修改键的客户端的redis_dirty_cas选项打开.
- 当客户端发送exec执行事务时,服务器会对客户端的redis_dirty_cas选项做检查
- 如何客户端的redis_dirty_cas选项已经被打开,那说明客户端监视的键至少有一个已经被修改,事务的安全性已经被破坏。 服务器会停止执行此事务,直接向客户端返回空,表示事务执行失败。
- 如果客户端的redis_dirty_case选项未被打开,说明被客户端监视的key都是安全的,正常执行事务。
1.3 事务的ACID性质
传统的关系型数据库中,常用ACID性质来检查事务功能的安全性
redis事务保证了其中的一致性(C)和隔离性(I), 但不保证原子性(A)和持久性(D)
- 原子性(Atomicity) Redis单个命令的执行时原子的,但是redis没有在事务上增加任何维护原子性的机制,所以redis事务不是原子的。 事务中所有命令执行成功则事务执行成功,但是若redis执行事务命令过程中被杀,它不提供事务中已执行命令的回滚操作。
- 一致性(Consistency) 根据持久化的rdb或者aof文件恢复到Redis内存中,数据和之前是一致的,所以Redis保证了一致性。
- 隔离性(Isolation) Redis是单进程程序,可以保证事务执行过程中不会被中断。
- 持久性(Durability), 即使有redis有rdb 和aof的持久化,但是两种方式都不能保证持久化的完备性。
2. 订阅和发布
2.1 频道的订阅和信息发布
subscribe 可以让客户端定义任意多个频道,每当有新信息发送到频道时,所有订阅次频道的客户端都会收到对应的信息。 publish 可以发送一个信息到某个频道。
2.1.1 subscribe 订阅频道
每个运行的Redis服务器都维护着一个redis.h/redisServer的结构体, redisServer中有个pubsub_channels字典。 这个字典保存了所有被订阅频道的信息, 其中,字典的键就是频道的名字,字典的值是一个链表,链表中保存了所有订阅这个频道的客户端。 当一个客户端调用subscribe时,程序就会把此客户端和pubsub_channels字典关联起来,把此客户端append到频道对应的列表中。
redisServer 结构体的部分定义如下:
struct redisServer {
// ...
dict *pubsub_channels;
list *pubsub_patterns;
// ...
};
订阅一个频道的伪代码如下:
def SUBSCRIBE (client, channels):
for channel in channels:
redisServer.pubsub_channels[channel].append(client)
2.1.2 publish 发布信息到频道
当调用publish channel message后,程序会定位到字典pubsub_channels中key为channel的元素,然后将信息发送给键channel对应的列表中的所有的客户端。
发布信息到一个频道的伪代码如下:
def PUBLISH (channel, message):
for client in pubsub_channels[channel]:
send_message(client, message)
unsubscribe可以取消对一个频道的订阅
2.2 模式的订阅和信息发布
2.2.1 psubscribe 订阅模式
redisServer.pubsub_patterns 是一个链表,里面存储了模式相关的信息。
pubsub_patterns链表中每个元素都是一个redis.h/pubsubPattern结构体,定义如下:
typedef struct pubsubPattern {
RedisClient *client;
robj *pattern;
}pubsubPattern;
其中, client保存了订阅了此模式的客户端,pattern 保存了被订阅的模式.
每次调用psubscribe 命令,程序都会创建一个包含客户端信息和被订阅的模式信息的pubsubPattern结构体, 并将此结构体添加到redisServer.pubsub_patterns链表中。
订阅模式的伪代码实现如下:
def PSUBSCRIBE(client, pattern):
pubsubPattern *tmp
tmp->client = client
tmp->pattern = pattern
redisServer.pubsub_patterns.append(tmp)
2.2.2 发送消息到模式和频道
多了可以订阅模式之后,publish发送一个消息后,不仅订阅频道的客户端可以收到消息,订阅了对应模式的客户端也会收到消息 完整的发布消息的实现如下:
def PUBLISH(channel, message);
for client in redisServer.pubsub_channels[channel]:
send_message(client, message)
for pattern, client in redisServer.pubsub_patterns:
if match(channel, pattern):
send_message(client, message)
punsubscribe 用于退订一个模式
4.3 lua脚本
4.3.1 Redis引入Lua脚本的意义
- 减少网络开销。可以将多个请求通过脚本的形式一次发送,减少网络时延, 也可以通过pipeline来实现一次发送多个命令。
- 原子操作。如前面介绍的,redis事务不能保证原子性; redis会将整个脚本作为一个整体执行,中间不会被其他命令插入。因此在编写脚本的过程中无需担心会出现竞态条件,无需使用事务。
- 复用。客户端发送的脚步会永久存在redis中,这样,其他客户端可以复用这一脚本而不需要使用代码完成相同的逻辑。
未完待续